✅Probeの概念整理

| 種類 | 目的 | 動作 | 用度 |
| startup | 起動が遅いアプリケーションの初期起動を保護する。 | startupProbeが成功するまで、Liveness/Readiness Probeは無効化される。失敗した場合はコンテナが再起動される。 | 起動に数分以上かかるレガシーアプリケーションで、起動中にLiveness Probeが動作して無限再起動ループに陥ることを防ぐために使用される。 |
| readiness | コンテナがトラフィックを受け入れる準備ができているかを確認する。 | 失敗した場合、そのPodはServiceのエンドポイントから除外される(Pod自体は維持されるがトラフィックは流れない)。 | 大量の設定ロードやDB接続初期化処理中のPodにトラフィックが流れてエラーが発生することを防ぐために使用される。 |
| liveness | コンテナが正常に稼働しているかを確認する。 | 失敗した場合、k8sが該当コンテナを終了させる。 | アプリケーションがデッドロックや応答不能状態に陥った場合に復旧するために使用される。 |
※レガシーアプリケーション:最新のクラウドネイティブ環境に最適化されていない、古い設計方式のソフトウェア
- 特徴:起動時に数百個のライブラリを読み込んだり、重い設定ファイルを読み込むなど、初期起動時間が非常に長い(例:数分以上)。
- 問題:Kubernetesの「迅速な復旧」という思想よりも、アプリケーションの「遅い起動速度」がボトルネックになることが多い。
※無限再起動ループ:StartupProbeが生まれた決定的な理由
- 状況:アプリケーションの起動に60秒かかる。
- 設定:LivenessProbeが10秒ごとにチェックし、3回失敗したら再起動するように設定されている(合計30秒の猶予)。
- 衝突:アプリケーションはまだ起動処理の途中(40秒時点)なのに、LivenessProbeは30秒の時点で「応答がない=死んでいる」判断してしまう。
- 結果:KubernetesがコンテナをKillして再起動する。
- 繰り返し:新しいコンテナも起動に60秒必要だが、30秒で再び停止されてしまう。これが無限再起動ループである。
※デッドロック:プロセスがリソースを占有したまま、互いに相手のリソースを待ち続け、無限待機状態に陥る現象。
- 状況:アプリケーションプロセス自体は起動しているが、内部ロジックが停止しており、どのリクエストにも応答できない状態。
- 解決:このときLivenessProbeが無応答を検知し、コンテナを再起動させることで強制的にリソースを解放し、プロセスを初期化する。
✅動作整理
1.startupProbe の実行(初期起動確認)
→ 成功するまで繰り返し実行
→ 失敗した場合はコンテナを再起動
2.startupProbe 成功後
→ livenessProbe と readinessProbe が継続的に実行される
3.readinessProbe 成功
→ Pod が Service のエンドポイントに追加される
→ トラフィックの受信が可能になる
4.livenessProbe 失敗
→ コンテナが再起動される
✅アプリログによるProbe動作の分析
▶事前準備
// HPA minReplica 1に変更 - Master Node
# kubectl patch -n anotherclass-123 hpa api-tester-1231-default -p '{"spec":{"minReplicas":1}}'
podが1に変更されている

▶podを削除

▶grafanaにてログを確認

1.アプリが起動し、データベースに接続される。
2.startupProbe成功する。

3.ConfigMapからユーザー情報を取得する。
4.readinessProbeは失敗し、livenessProbeは成功する。
※ユーザー初期化の区間では、readinessProbeが1回失敗する。
5.readinessProbeが成功し、livenessProbeも成功する。
▶考慮事項
1.readinessProbeとlivenessProbeは、アプリが停止するまで動作し続けるため、ロジックは軽量にする必要がある。
2.アプリ開発者とk8sの管理者が異なる場合は、上記について十分に協議する必要がある。
✅アプリ動作を中心としたProbeの理解
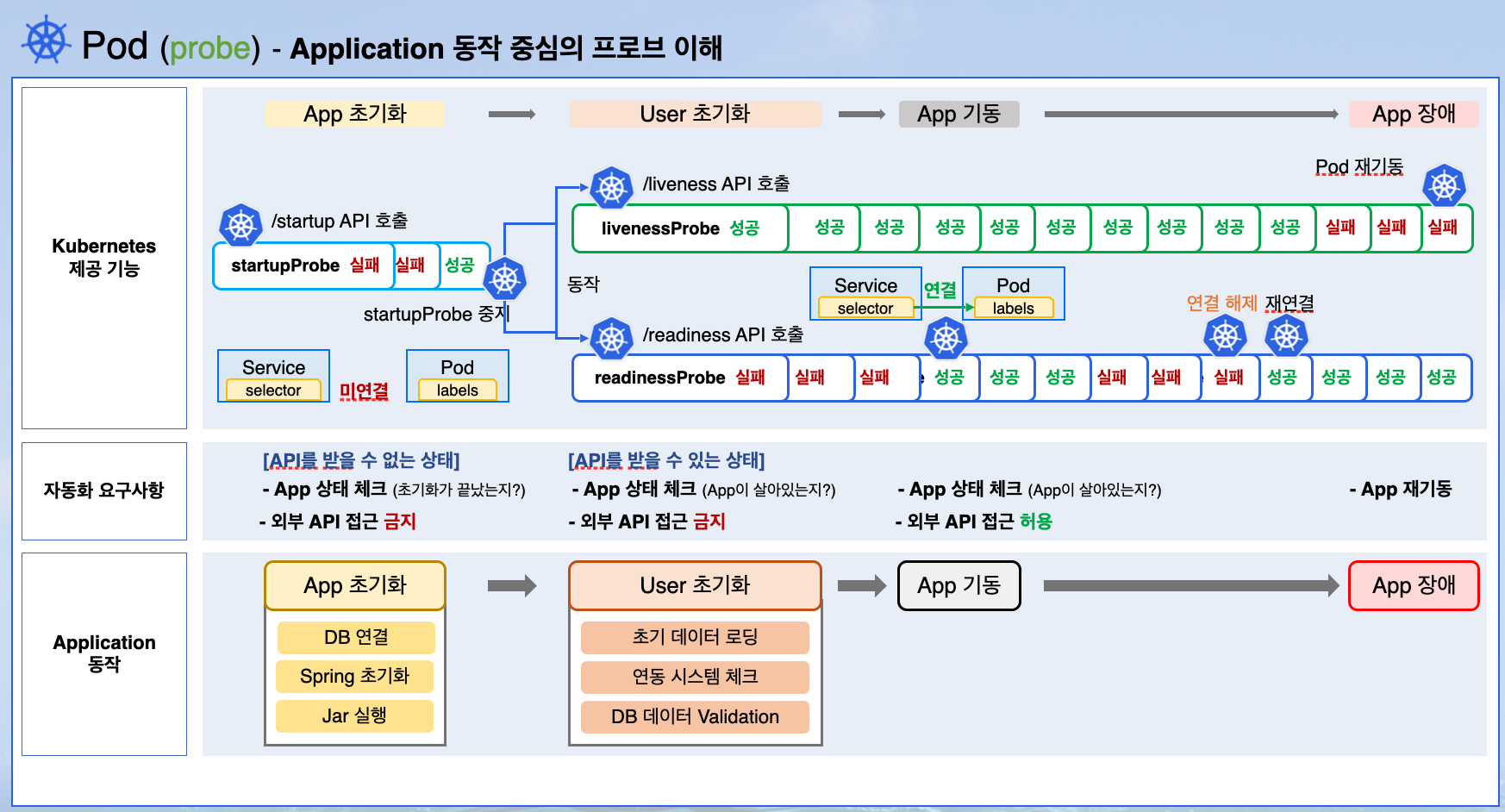
▶ Master Nodeにて実行
1.podを削除

2.Appが再起動し、初期化されている。

// 3. API - 外部のAPI失敗
# curl http://192.168.56.30:31231/hello
// 4.内部のAPI成功
# kubectl exec -n anotherclass-123 -it <my-pod-name> -- curl localhost:8080/hello
// 5.外部のAPI成功
# curl http://192.168.56.30:31231/hello

// 6.トラフィックを停止(アプリ内部のisAppReadyをFalseに変更する)
# curl http://192.168.56.30:31231/traffic-offトラフィックを停止し、外部APIを受け付けられない状態となる。


// 7.トラフィックを再開(アプリ内部のisAppReadyをTrueに変更する)
# kubectl exec -n anotherclass-123 -it <my-pod-name> -- curl localhost:8080/traffic-onトラフィックを再開し、外部APIを受け付けられるかを確認する。



8.障害発生(アプリ内部のisAppLiveをFalseに変更する)
# curl http://192.168.56.30:31231/server-error設定に応じて、livenessProbeが3回失敗すると、Podが再起動される。




今後検討すべきポイント
アプリに突発的な一時障害が発生した場合、瞬間的に負荷が高まり、外部APIが継続的に流入すると状況が悪化する可能性がある。
その結果、システムが停止してしまう場合もあれば、時間の経過とともに自動的に回復する場合もある。
しかし、この過程でlivenessProbeやreadinessProbeが失敗すると、k8sはPodを再起動する。
この場合、もしprobeがなければ正常に復旧できた可能性があるにもかかわらず、アプリで処理中の作業はすべて失敗してしまう。
(※失敗させずに処理を完了させる仕組みを実装することも可能)
対策
この状況を解決するためには、一時的な高負荷時において、readinessProbeは外部トラフィックを遮断し負荷を軽減するため、そのままで問題ない。
一方で、livenessProbeのチェック間隔をreadinessProbeと同じにしないことが重要である。
失敗と判定されるまでの時間をやや長めに設定し、再起動が行われるまでの猶予を持たせることで、不要な再起動を防ぐことができる。
✅Kubernetes Probe 実務まとめ
🚀startupProbe
アプリの起動時間が遅い場合に「まだ落とさないように保護する」
実務例
Spring Bootアプリ起動時にDB接続や初期化で30〜60秒かかるケース
- startupProbeがない場合 → livenessProbeが先に失敗 → 再起動ループ
- startupProbeがある場合 → 起動完了まで待機してくれる
🚦readinessProbe
「トラフィックを受けても良い状態かどうか」を判断する
実務例
アプリは起動しているが:
- DBがまだ接続されていない
- キャッシュのロード中
この状態でトラフィックを受けると障害になる
readiness失敗時:
- サービスの対象から除外される
- トラフィックは流れない
💀 livenessProbe
「アプリが正常に動作していない場合に再起動する」
実務例
- デッドロック発生
- メモリリーク
- 応答なし状態
liveness失敗時:
- コンテナが自動的に再起動される
'k8s > archive_2' 카테고리의 다른 글
| Probe,Service,Secret,HPA (0) | 2026.04.18 |
|---|---|
| PV/PVC、Deployment、Service (0) | 2026.04.16 |
| Configmap、Secret (0) | 2026.04.15 |
| オブジェクトの理解 (0) | 2026.04.13 |
| Kubernetesの利便性 (0) | 2026.04.13 |