■PVC、PV

1. ローカルボリューム (Local Volume)
最高のパフォーマンスを実現するため、ノードのローカルディスクを直接占有する方式。データの整合性を維持するため、nodeAffinity と WaitForFirstConsumer による精緻なスケジューリングが強制される。
2. ホストパス (HostPath)
ノードのファイルシステムへ直接アクセスする経路を提供するツール。強力なパフォーマンスと制御権を得られる反面、コンテナの隔離原則を損なうセキュリティ上の最大の弱点 (Security Hole) となる。
- 運用の原則: リスクが高いため、可能な限り使用を避けること。
- 制限事項: 使用が不可避な場合は、範囲を最小限に絞り、必ず ReadOnly でマウントすること。
- ポリシーの注意点: AdmissionPolicyで制限をかける際、ReadOnly設定を有効に機能させるためには volumeMounts の指定が必須。
3. PVとPVCの必要性
Kubernetesは、「インフラ専門家」と「アプリ開発者」の役割を分離するために PV と PVC を設計した。
- PV (インフラ側の領域): 「100GBの高性能EBSを10個用意した。」(物理リソース)
- PVC (アプリ側の領域): 「詳細は問わないが、とにかく『高性能な20GB』を貸してくれ。」(要求書)
【分離のメリット】
開発者はインフラが AWS なのか Azure なのかを意識する必要がない。単に PVC を作成するだけで、Kubernetesが最適な PV を自動で割り当てる。
■local動作確認
// 1.ファイル生成
# http://192.168.56.30:31231/create-file-pod
# http://192.168.56.30:31231/create-file-pv
// 2.Container 一時フォルダの確認
# kubectl exec -n anotherclass-123 -it <pod-name> -- ls /usr/src/myapp/tmp
// 2.Container 永続保存フォルダの確認
# kubectl exec -n anotherclass-123 -it <pod-name> -- ls /usr/src/myapp/files/dev
// 2.マスターノードのフォルダ確認
# ls /root/k8s-local-volume/1231
// 3. Pod削除
# kubectl delete -n anotherclass-123 pod <pod-name>
// 4. ファイルの照会
# http://192.168.56.30:31231/list-file-pod
# http://192.168.56.30:31231/list-file-pv
■hostpath動作確認
deploymentを以下のように修正
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: anotherclass-123
name: api-tester-1231
spec:
template:
spec:
nodeSelector:
kubernetes.io/hostname: k8s-master
containers:
- name: api-tester-1231
volumeMounts:
- name: files
mountPath: /usr/src/myapp/files/dev
- name: secret-datasource
mountPath: /usr/src/myapp/datasource
volumes:
- name: files
hostPath:
path: /root/k8s-local-volume/1231
- name: secret-datasource
secret:
secretName: api-tester-1231-postgresql
▶ nodeAffinity
노드 어피니티를 사용해 노드에 파드 할당
이 문서는 쿠버네티스 클러스터의 특정 노드에 노드 어피니티를 사용해 쿠버네티스 파드를 할당하는 방법을 설명한다. 시작하기 전에 쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이
kubernetes.io
▶ local
볼륨
컨테이너 내의 디스크에 있는 파일은 임시적이며, 컨테이너에서 실행될 때 애플리케이션에 적지 않은 몇 가지 문제가 발생한다. 한 가지 문제는 컨테이너가 크래시될 때 파일이 손실된다는 것
kubernetes.io
1.Update
디플로이먼트
디플로이먼트는 애플리케이션 워크로드를 실행하기 위해 여러 파드 집합을 관리하며, 보통 스테이트리스(stateless) 애플리케이션을 대상으로 한다.
kubernetes.io

Deploymentのアップデートトリガー
結論: spec.template 配下の内容が変更された場合のみ、新しいリビジョンへのアップデートが実行される。
- 仕組み: Kubernetesは template の内容をハッシュ化して監視している。このハッシュ値が変わると、新しい ReplicaSet を作成し、ローリングアップデートを開始する。
- 主な変更例:
- コンテナイメージのタグ(バージョン)変更
- 環境変数 (env) や設定ファイル (ConfigMap/Secret) の参照変更
- リソース制限 (resources) やマウントパスの修正
- 注意点: replicas(個数)の変更は template 外の設定であるため、Podの再作成(アップデート)は行われず、単なるスケーリングとして処理される。
1-1. Recreate
- 動作: 既存のPodをすべて削除した後、新しいPodを生成する。
- ダウンタイム: 旧Podの削除から新Podの起動完了までの間、サービスが一時中断するダウンタイムが発生する。
- 特徴: 新旧バージョンが同時に存在しないため、データの整合性維持には有利。
1-2. RollingUpdate
- 動作: Podを1つずつ順番に入れ替える。新Podの起動を確認してから旧Podを削除する方式。
- メリット: サービスを停止させずに更新が可能(ゼロダウンタイム)。
- デメリット/注意点: 1. リソース使用量: 更新中、一時的に新旧Podが共存するため、リソース消費量が増加する。 2. バージョンの混在: アップデート中、新旧両方のバージョンにトラフィックが分散される。そのため、アプリケーション間での互換性維持が必須。
RollingUpdateの細部制御パラメーター
① maxSurge (最大増分)
- アップデート中に、意図したPod数よりどれだけ多く生成できるかを定義。
- メリット: 新バージョンの準備を先行させるため、デプロイが速くなる。
- 注意点: 一時的にリソース(CPU/メモリ)の消費量が増加する。
② maxUnavailable (最大不可分)
- アップデート中に、意図したPod数よりどれだけ少なく維持できるかを定義。
- メリット: 既存のPodを先に削除するため、追加リソースを抑えられる。
- 注意点: デプロイ中、リクエストを処理できる容量が減少し、パフォーマンスに影響が出る可能性がある。
RollingUpdateによるブルーグリーン配備の再現
結論: maxSurge を100%に設定することで、事実上のブルーグリーン配備が可能になる。
① 設定値:
- maxSurge: 100% (または replicas数以上の値)
- maxUnavailable: 0
② メリット:
- 可用性の最大化: 更新中、常にサービス容量を100%以上維持できる。
- 切り替えの高速化: 新バージョンが全て揃ってから旧バージョンを削除するため、実質的な切り替え時間が非常に短い。
③ 運用の注意点:
- 一時的なリソース不足: デプロイ中、Pod数が2倍になるため、クラスターのノードリソース(CPU/メモリ)に十分な空きが必要。
- ロールバック: 完全なブルーグリーン(別リソース管理)に比べると、障害発生時の切り戻しに若干の時間を要する。
■RollingUpdate動作確認
// 1.HPAの minReplicas を 2 に変更
# kubectl patch -n anotherclass-123 hpa api-tester-1231-default -p '{"spec":{"minReplicas":2}}'
// 2.Deployment scale コマンド
# kubectl scale -n anotherclass-123 deployment api-tester-1231 --replicas=2
// 3.editモードで直接修正
# kubectl edit -n anotherclass-123 deployment api-tester-1231
// 4.継続的に Version を呼び出し (アップデート中のリターン値を観察)
# while true; do curl http://192.168.56.30:31231/version; sleep 2; echo ''; done;
// 5.別途リモートコンソールを開いてアップデートを実行
# kubectl set image -n anotherclass-123 deployment/api-tester-1231 api-tester-1231=1pro/api-tester:v2.0.0
# kubectl set image -n anotherclass-123 deployment/api-tester-1231
// 6.maxUnavailable: 0%, maxSurge: 100%
piVersion: apps/v1
kind: Deployment
metadata:
namespace: anotherclass-123
name: api-tester-1231
spec:
replicas: 2
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25% -> 0% # 修正
maxSurge: 25% -> 100% # 修正
# kubectl set image -n anotherclass-123 deployment/api-tester-1231 api-tester-1231=1pro/api-tester:v1.0.0
■Recreate動作確認
// 1.Recreate
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: anotherclass-123
name: api-tester-1231
spec:
replicas: 2
strategy:
type: RollingUpdate -> Recreate # 修正
rollingUpdate: # 削除
maxUnavailable: 0% # 削除
maxSurge: 100% # 削除
# kubectl set image -n anotherclass-123 deployment/api-tester-1231 api-tester-1231=1pro/api-tester:v2.0.0
// 2.Rollback
# kubectl rollout undo -n anotherclass-123 deployment/api-tester-1231
■Service
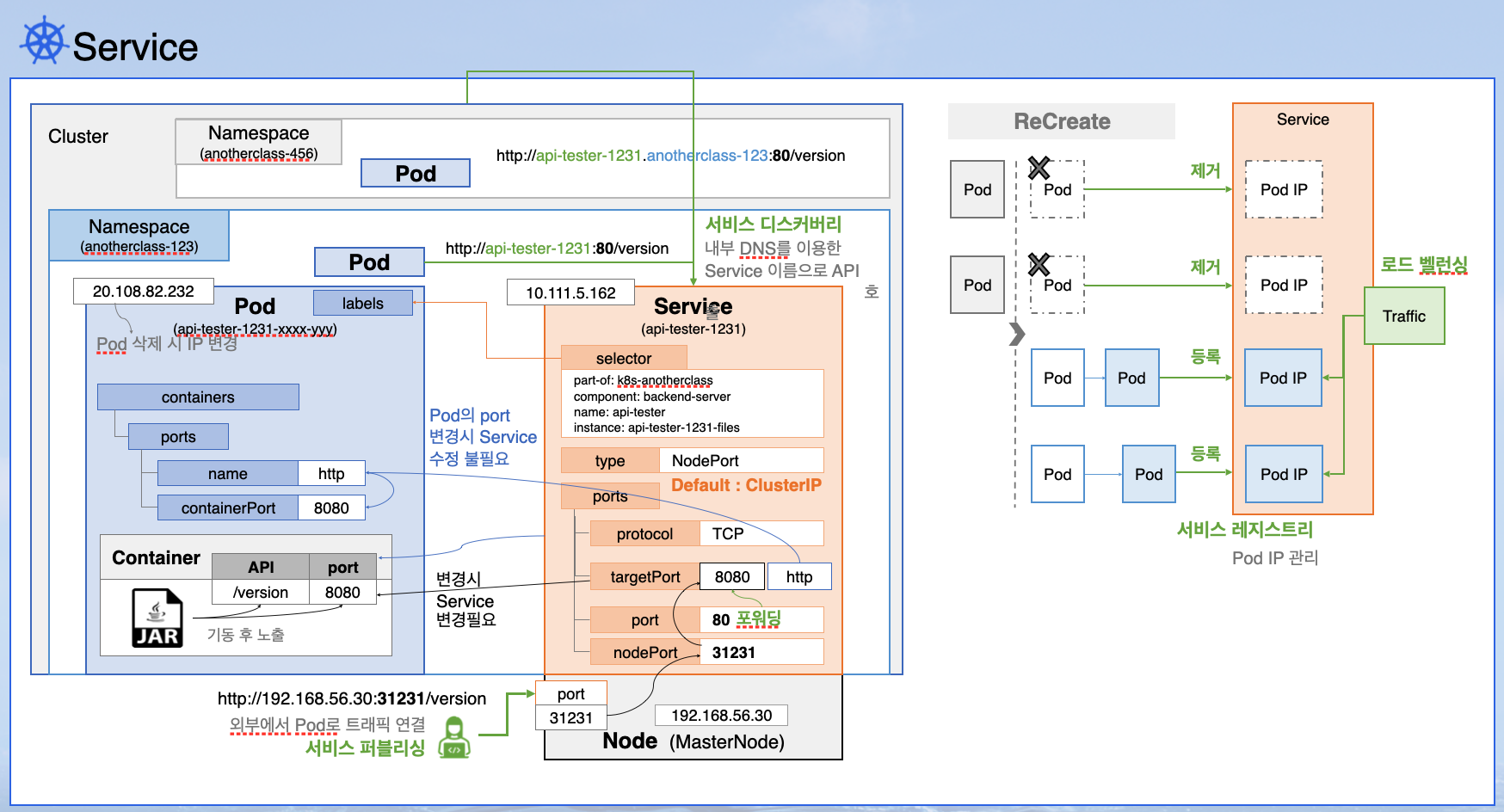
■動作確認
// 1.Pod内部でService名でAPI呼び出し
# kubectl exec -it -n anotherclass-123 <pod名> -- /bin/bash
# curl http://api-tester-1231:80/version
// 2.DeploymentでPodのportsをすべて削除し、ServiceのtargetPortをhttpから8080に変更
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: anotherclass-123
name: api-tester-1231
spec:
template:
spec:
nodeSelector:
kubernetes.io/hostname: k8s-master
containers:
- name: api-tester-1231
ports: // 削除
- name: http // 削除
containerPort: 8080 // 削除
---
apiVersion: v1
kind: Service
metadata:
namespace: anotherclass-123
name: api-tester-1231
spec:
ports:
- port: 80
targetPort: http -> 8080 // 변경
nodePort: 31231
type: NodePort
▶ dns
서비스
외부와 접하는 단일 엔드포인트 뒤에 있는 클러스터에서 실행되는 애플리케이션을 노출시키며, 이는 워크로드가 여러 백엔드로 나뉘어 있는 경우에도 가능하다.
kubernetes.io
서비스 및 파드용 DNS
워크로드는 DNS를 사용하여 클러스터 내의 서비스들을 발견할 수 있다; 이 페이지는 이것이 어떻게 동작하는지를 설명한다.
kubernetes.io
▶ 서비스 퍼블리싱
서비스
외부와 접하는 단일 엔드포인트 뒤에 있는 클러스터에서 실행되는 애플리케이션을 노출시키며, 이는 워크로드가 여러 백엔드로 나뉘어 있는 경우에도 가능하다.
kubernetes.io
▶ NodePort (基本値 : 30000-32767)
서비스
외부와 접하는 단일 엔드포인트 뒤에 있는 클러스터에서 실행되는 애플리케이션을 노출시키며, 이는 워크로드가 여러 백엔드로 나뉘어 있는 경우에도 가능하다.
kubernetes.io
■HPA

HPA指標選定における考察と実務的ガイドライン
1. メモリが負荷の絶対的指標ではない理由 (メモリの特性)
メモリはCPUと異なり、「処理が終われば即座に0%に落ちる」リソースではない。
- ガベージコレクション (GC) の影響: 特にJava (Spring) 等の言語では、メモリが限界に達するまで清掃(GC)をあえて行わない。外部から見ると「メモリ使用率90%=過負荷」に見えるが、実際にはアプリが単にメモリを保持(Hold)しているだけの場合が多い。
- キャッシュ (Caching): パフォーマンス向上のため、一度読み込んだデータをメモリに蓄積する。これは「負荷」ではなく「最適化」された状態だが、これを負荷と誤認してHPAを作動させると、リソースの浪費に繋がる。
- 結論: メモリ使用率のみを基準にポッドを増やすと、新しく起動したポッドもすぐにメモリを満たしてしまい、**「HPAの無限増殖(Infinite Scaling)」**という地獄を招く恐れがある。
2. CPU指標だけでは不十分な理由 (CPUの特性)
CPU使用率がすべての負荷を代弁できるわけではない。
- I/O Bound(I/Oバウンド)タスク: データベース(DB)からのデータ取得待ち等、待機時間が長いアプリの場合。この時、CPU使用率は低いが、待機中のユーザーリクエストは数千件に達することもある(CPUは遊んでいるが、サービスは麻痺している状態)。
- 基準の相違: 演算の多いAIアプリでは「CPU 90%」が正常だが、単純なチャットアプリでは「CPU 20%」でも危険信号である。つまり、アプリの特性によって負荷の定義が異なる。
3. 実務でのベストプラクティス (Custom Metrics)
現場のエンジニアは、CPU/メモリといった標準メトリクスだけでなく、**「カスタムメトリクス(Custom Metrics)」**を活用してHPAを運用する。
- リクエスト処理数 (Requests Per Second - RPS): 「秒間1,000件以上のリクエストが流入したらポッドを増設する」。最も直感的かつ正確な負荷測定方法。
- キューの待機列 (Queue Length): 「メッセージキューに滞留しているタスクが100件を超えたら、処理用ポッドを増設する」。
■動作確認
▶ 負荷発生
// 1.3分間負荷発生
# curl http://192.168.56.30:31231/cpu-load?min=3
// 2.負荷確認
# kubectl top -n anotherclass-123 pods
# kubectl get hpa -n anotherclass-123
// Prometheus
Grafana > Home > Dashboards > [Default] Kubernetes / Compute Resources / Pod
// Replica
Grafana > Home > Dashboards > New > Import クリック
- Import via grafana.comに 17125 入力後 [Load] クリック
▶ HPAの計算式
Horizontal Pod Autoscaling
쿠버네티스에서, HorizontalPodAutoscaler 는 워크로드 리소스(예: 디플로이먼트 또는 스테이트풀셋)를 자동으로 업데이트하며, 워크로드의 크기를 수요에 맞게 자동으로 스케일링하는 것을 목표로 한
kubernetes.io
'k8s > archive_2' 카테고리의 다른 글
| CICD-SERVER構築/検証 (0) | 2026.04.19 |
|---|---|
| Probe,Service,Secret,HPA (0) | 2026.04.18 |
| Configmap、Secret (0) | 2026.04.15 |
| Probe (0) | 2026.04.15 |
| オブジェクトの理解 (0) | 2026.04.13 |