
CNCFプロジェクトの分類基準および選定要件
上の図は、k8sのエコシステムにおいてカテゴリ別に多用される製品を分類したものであり、以下の基準に基づいて選定されている。
プロジェクトの区分
- CNCFプロジェクト
- CNCFメンバー企業および非メンバー企業の製品
CNCFプロジェクトの成熟度レベル (Maturity Levels)
CNCFプロジェクトは、その成熟度に応じて以下の4つの段階に分けられる。
- Graduated Projects (卒業段階): 組織としての成熟度、広範な採用実績、および強固なガバナンスが証明された最上位プロジェクト。
- Incubating Projects (育成段階): 実際に本番環境での使用実績があり、成長性と安定性を兼ね備えたプロジェクト。
- Sandbox Projects (サンドボックス段階): 実験的な段階であり、CNCFの技術監督委員会(TOC)によって有望だと判断された初期プロジェクト。
- Archived Projects (アーカイブ段階): 開発が終了したか、他のプロジェクトに統合されるなどして、第一線を退いたプロジェクト。
CNCFメンバーと非メンバーの違い
- メンバーと非メンバーの差: 主にCNCFに対して会費を支払い、製品のプロモーションや各グレードに応じた特典を享受しているかどうかの違いである。
- エコシステムへの影響力: * 非メンバーの製品であっても、k8sの標準エコシステムにおいて極めて高い影響力を持つデファクトスタンダード(事実上の標準)製品が多数存在する。
実際のプロジェクトで発生する構造的問題(モニタリング・ロギング)とその解決策
1. 開発とモニタリングの密結合 (Coupling)
- 従来の問題: 開発者がソースコード内に監視用ライブラリを直接組み込んだり、特定の監視サーバのIPアドレスをハードコー딩する必要があった。これにより、監視基盤の変更がアプリ側にまで影響を及ぼす構造になっていた。
- K8sによる解決: 標準化されたメトリクス公開 (Exposition)。K8s環境では、アプリが特定のエンドポイント(/metrics)にデータを露出させておけば、監視システムがそれを回収しに行く Pull型 を採用している。開発者は監視サーバの所在を意識する必要はなく、規約に従ってデータを公開するだけで切り離し(Decoupling)が完了する。
2. 未経験の監視システム構築による負担
- 従来の問題: 監視のために、個別のデータベース、収集機、アラートサーバをプロジェクトごとにゼロから設計・構築しなければならず、開発チームにとって大きなオーバーヘッドとなっていた。
- K8sによる解決: OperatorパターンとHelmの活用。kube-prometheus-stack 等のパッケージを利用することで、業界標準の監視セットアップが即座に完了する。開発・本番環境ともに共通の Infrastructure as Code (IaC) でデプロイされるため、「未知のシステムを構築する」という負担はなくなり、プラットフォームが提供する「標準ユーティリティ」を利用する感覚で運用できる。
3. 多様なアプリケーション監視の断片化
- 従来の問題: Java、Go、Python、あるいはDBなど、アプリやミドルウェアごとに監視手法が異なり、管理範囲がバラバラで一貫性がなかった。
- K8sによる解決: サービスディスカバリ (Service Discovery)。これはK8sのコア機能である。監視システムがK8s APIと通信し、クラスター内で稼働中の全Podを自動的に認識する。K8s上で動作してさえいれば、言語や種類を問わず Label(ラベル) を基準に、単一のダッシュボードで一貫した管理・監視が可能になる。
上記の構造的な問題点の解決策を検証してみる。
※ 本インストールではStorage連携を別途割り当てていないため、VMが再起動されると、既存の保存済みログデータは消失します。
[1] GitHubからPrometheus(Grafana付き)、Loki-Stackのyamlをダウンロード
▶ [k8s-master] コンソールに接続後、以下のコマンドを実行
✅gitインストール
[root@k8s-master ~]# yum -y install git
#ローカルリポジトリの作成
# git init
# git config --global init.defaultBranch main
# remote 追加 ([root@k8s-master ~]#)
# git remote add -f origin https://github.com/lioncubKR/kubernetes.git
# sparse checkout 設定
# git config core.sparseCheckout true
# echo "monitoring/ground/k8s-1.27/prometheus-2.44.0" >> .git/info/sparse-checkout
# echo "monitoring/ground/k8s-1.27/loki-stack-2.6.1" >> .git/info/sparse-checkout
# ダウンロード
# git pull origin main
[2] Prometheus(with Grafana) インストール
- Github : https://github.com/prometheus-operator/kube-prometheus/tree/release-0.14
GitHub - prometheus-operator/kube-prometheus at release-0.14
Use Prometheus to monitor Kubernetes and applications running on Kubernetes - prometheus-operator/kube-prometheus
github.com
# インストール ([root@k8s-master ~]#)
# kubectl apply --server-side -f monitoring/ground/k8s-1.27/prometheus-2.44.0/manifests/setup
# kubectl wait --for condition=Established --all CustomResourceDefinition --namespace=monitoring
# kubectl apply -f monitoring/ground/k8s-1.27/prometheus-2.44.0/manifests
# インストール確認 ([root@k8s-master ~]#)
# kubectl get pods -n monitoring
▶ 確認結果

[3] Loki-Stack インストール
# インストール ([root@k8s-master ~]#)
# kubectl apply -f monitoring/ground/k8s-1.27/loki-stack-2.6.1
# インストール確認 ([root@k8s-master ~]#)
# kubectl get pods -n loki-stack
▶ 確認結果

[4] Grafana 接続
▶ URL : http://192.168.56.30:30001
▶ ログイン情報 :
ID: admin
PW: admin
▶ 確認結果

[5] GrafanaでLoki-Stackを接続
▶ Connect data : Home > Connections > Connect data
▶ 検索欄に [loki] 入力後に押下する。

▶ 「Create a Loki data source」を押下する。

▶ URL入力
「http://loki-stack.loki-stack:3100」

▶ 下段の「Save & Test」

※ 削除する必要がある場合は、以下のコマンドを入力
- Prometheus(Grafana付き)、Loki-Stackの削除
▶ [k8s-master] コンソールに接続後、以下のコマンドを入力
# Prometheusの削除
# kubectl delete --ignore-not-found=true -f monitoring/ground/k8s-1.27/prometheus-2.44.0/manifests -f monitoring/ground/k8s-1.27/prometheus-2.44.0/manifests/setup
# Loki-Stackの削除
# kubectl delete -f monitoring/ground/k8s-1.27/loki-stack-2.6.1
[6] k8sのDashboardでアプリの配布テスト
▶ Dashboardにアクセス → Namespace[default]を選択 → [+]ボタンをクリック → [入力から作成]を選択 → YAMLファイルを貼り付け → アップロード

▶ yaml ファイル
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-1-2-2-1
spec:
selector:
matchLabels:
app: '1.2.2.1'
replicas: 2
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: '1.2.2.1'
spec:
containers:
- name: app-1-2-2-1
image: 1pro/app
imagePullPolicy: Always
ports:
- name: http
containerPort: 8080
startupProbe:
httpGet:
path: "/ready"
port: http
failureThreshold: 20
livenessProbe:
httpGet:
path: "/ready"
port: http
readinessProbe:
httpGet:
path: "/ready"
port: http
resources:
requests:
memory: "100Mi"
cpu: "100m"
limits:
memory: "200Mi"
cpu: "200m"
---
apiVersion: v1
kind: Service
metadata:
name: app-1-2-2-1
spec:
selector:
app: '1.2.2.1'
ports:
- port: 8080
targetPort: 8080
nodePort: 31221
type: NodePort
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: app-1-2-2-1
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: app-1-2-2-1
minReplicas: 2
maxReplicas: 4
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 40
▶ 結果確認
1.DashBoard

2.Grafana
3.Loki
k8sの主要機能

上記のYAMLファイルを用いて主要機能を検証
[1] アプリに継続的にトラフィックを送信(Traffic Routing)
# while true; do curl http://192.168.56.30:31221/hostname; sleep 2; echo ''; done;
※ トラフィックアルゴリズムについて:現在はiptablesモードで動作しているため、トラフィックはPodにランダムに分散される。https://kubernetes.io/ko/docs/reference/networking/virtual-ips/
가상 IP 및 서비스 프록시
쿠버네티스 클러스터의 모든 노드는 kube-proxy를 실행한다(kube-proxy를 대체하는 구성요소를 직접 배포한 경우가 아니라면). kube-proxy는 ExternalName 외의 type의 서비스를 위한 가상 IP 메커니즘의 구현
kubernetes.io
トラフィックが分散されていることを確認できる。

Podを1つ削除すると、稼働中のPodにのみトラフィックが送られる。

新しいPodが作成され、正常に起動すると、再びトラフィックが分散されることを確認できる。


[2] アプリにメモリリークを発生させる(Self-Healing)
# curl 192.168.56.30:31221/memory-leak
Podが再起動されたことを確認できる。

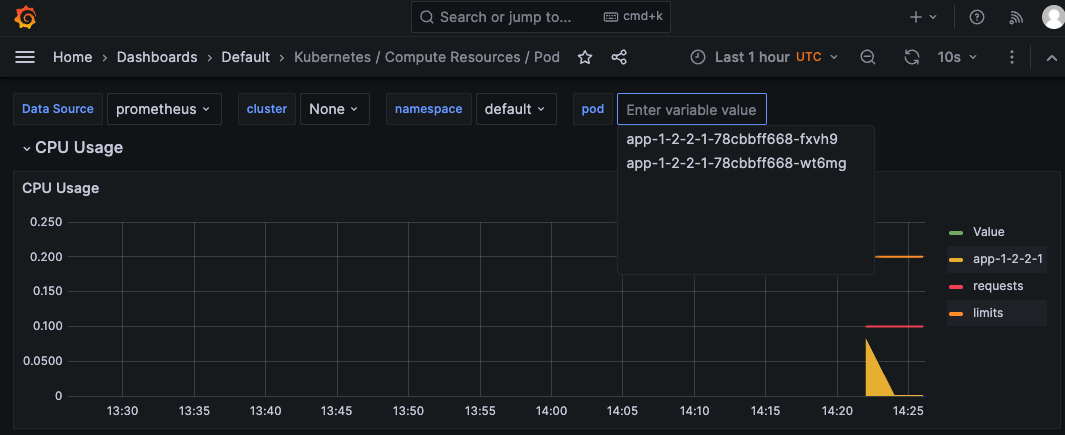
該当Podのメモリ使用量が急増した区間をGrafanaで確認し、Lokiでログを確認する。


[3] アプリに負荷をかける(AutoScaling)
# curl 192.168.56.30:31221/cpu-load
CPU負荷により、Podが4つまで増加した。

CPUが安定した後、最小維持Pod数の2つに戻った。

[4-1] アプリ イメージ アップデート(RollingUpdate)
# kubectl set image -n default deployment/app-1-2-2-1 app-1-2-2-1=1pro/app-update
更新されたイメージのPodが起動した後、既存のPodが削除されることを確認できる。そのため、イメージ更新中でもトラフィックは途切れない。



[4-2] 起動不可 アプリ アップデート (RollingUpdate)
# kubectl set image -n default deployment/app-1-2-2-1 app-1-2-2-1=1pro/app-error
正常に起動せず、再起動を繰り返している。
※k8sは新しいイメージの正常起動を確認した後に既存イメージを切り替えるため、作業者のミスがあっても補完される。

▶ 更新を中止し、ロールバックする。
# kubectl rollout undo -n default deployment/app-1-2-2-1'k8s > archive_2' 카테고리의 다른 글
| Probe,Service,Secret,HPA (0) | 2026.04.18 |
|---|---|
| PV/PVC、Deployment、Service (0) | 2026.04.16 |
| Configmap、Secret (0) | 2026.04.15 |
| Probe (0) | 2026.04.15 |
| オブジェクトの理解 (0) | 2026.04.13 |